Rapid
Execution Engine
The
new architecture permitted the Pentium 4 to run the Arithmetic Logic Units
(ALUs) two times the frequency of the Processors core it self. This means
that the Arithmetic Logic Units on a Pentium 4 running at 1.5 are operating
at 3GHz with a latency that is half the duration of the core clock. This can
be directly translated in higher through and reduced latency of execution.
400MHz
Front Side Bus
One of the most talked features of the Pentium 4 is its 400MHz BUS. The Pentium
III Processors 133MHz bus, which is 64-bit Wide, is capable of delivering
1.06GB/S of data. The Architecture of the Pentium 4 is somewhat different.
The Pentium 4s bus is clocked at only 100MHz at also 64-bit Wide, what differs
here is that the 100MHz is quad pumped and is capable of achieving a whooping
3.2GB/s peak.
Advanced Transfer Cache
Intels Pentium III features 8KB of L1 data
cache. This is half the size of what the Pentium III features. This may seem
a bit confusing at first, but smaller caches have lower latencies. This was
done in order to decrease the latency of the L1 memory, this should result
in an improved transfer rate but at the same time, the little size (8K) might
not be enough for some specific tasks.
This is where the L2 memory comes in mind. The Pentium 4, like the Pentium
III (Coppermine), spots 256k of on-die-cache on a 256-bit bus. However, there
is a difference between both. The new architecture of the Pentium 4 permits
to transfer data on each clock, compared to the Pentium III (Coppermine) that
is transferring data on every other Cycle.
|
Intel
Pentium 4 1.5GHz
|
256-bit (32 byte) x 1 x 1.5GHz = 48GB/s
|
|
Intel
Pentium 3 1000GHz
|
256-bit (32 byte) x .5 x 1GHz = 16GB/s
|
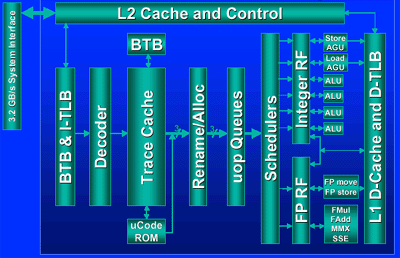
Execution Trace Cache
This technology caches decoded x86 instructions (micro-ops), thus removing
the latency associated with the instruction decoder from the execution loop.
The Execution Trace Cache stores the micro-ops in the path of program execution
flow, where the results of branches in the code are integrated into the same
cache line.
Execution Trace Cache is another handy technique Intel implemented in its
new Architecture to ease the penalty of miss-Predicted Branch instructions.
On older Intel processors, based on previous architectures, if the branch
instruction was miss-predicted, the processor needed to start the process
from the beginning. The NetBurst architectures permits to go directly through
the Execution Trace Cache Technology to retrieve the micro-op and then send
it through execution pipeline without having to restart the process from the
first phase.